

Sik Ho Tsang Medium
Llama-2-Chat which is optimized for dialogue has shown similar performance to popular closed-source models like ChatGPT and PaLM. We will fine-tune the Llama-2 7B Chat model in this guide Steer the Fine-tune with Prompt Engineering When it comes to fine. LLaMA 20 was released last week setting the benchmark for the best open source OS language model Heres a guide on how you can. Open Foundation and Fine-Tuned Chat Models In this work we develop and release Llama 2 a collection of pretrained and fine-tuned. For LLaMA 2 the answer is yes This is one of its attributes that makes it significant While the exact license is Metas own and not one of the..
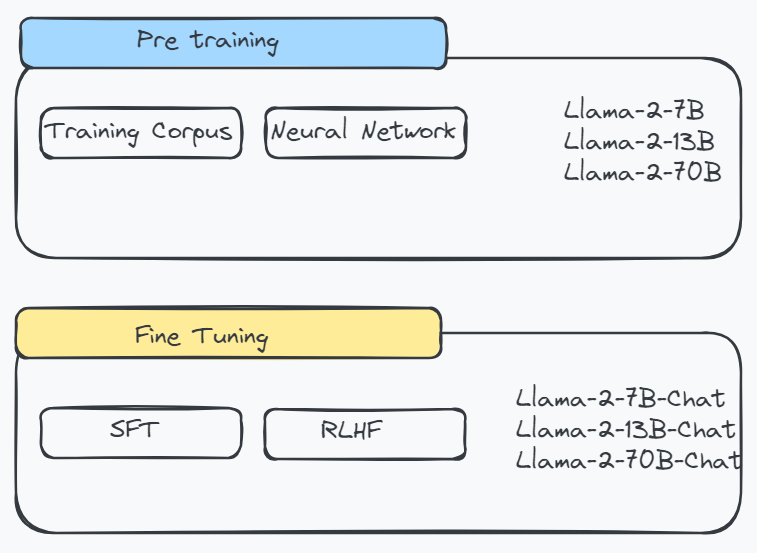
You can easily try the Big Llama 2 Model 70 billion parameters in this Space or in the playground embedded below. App Files Files Community 48 Discover amazing ML apps made by the community Spaces. The Llama2 model was proposed in LLaMA Open Foundation and Fine-Tuned Chat Models by Hugo Touvron Louis Martin Kevin Stone Peter Albert. Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and fine-tuned generative text models. Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters..
Llama 2 Community License Agreement Agreement means the terms and conditions for use reproduction distribution and. Llama 2 is also available under a permissive commercial license whereas Llama 1 was limited to non-commercial use Llama 2 is capable of processing longer prompts than Llama 1 and is. Llama 2 is being released with a very permissive community license and is available for commercial use The code pretrained models and fine-tuned models are all being. To download Llama 2 model artifacts from Kaggle you must first request a using the same email address as your Kaggle account After doing so you can request access to models. Metas LLaMa 2 license is not Open Source OSI is pleased to see that Meta is lowering barriers for access to powerful AI systems Unfortunately the tech giant has created the..
All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have. Im referencing GPT4-32ks max context size The context size does seem to pose an issue but Ive. Its likely that you can fine-tune the Llama 2-13B model using LoRA or QLoRA fine-tuning with a single consumer. It was made adjustable as a new command line param here. In this post were going to cover everything Ive learned while exploring Llama 2 including how to. Llama 213B takes longer to fine-tune when compared to Llama 27B owing to the differences in their. The Llama 2 release introduces a family of pretrained and fine-tuned LLMs ranging in scale from 7B to 70B. In the case of Llama 2 the context size measured in the number of tokens has expanded significantly..
Medium




Komentar